The DevStack product is OpenStack Powered. OpenStack is a platform that allows you to build a cloud environment by virtualizing existing physical resources such as servers, networks, and storage, and manage virtual resources through dashboards and APIs, and provides a service environment similar to AWS (Amazon Web Services). Our cloud service contains OpenStack software and has been validated through testing to provide API compatibility for OpenStack core services since 2015.
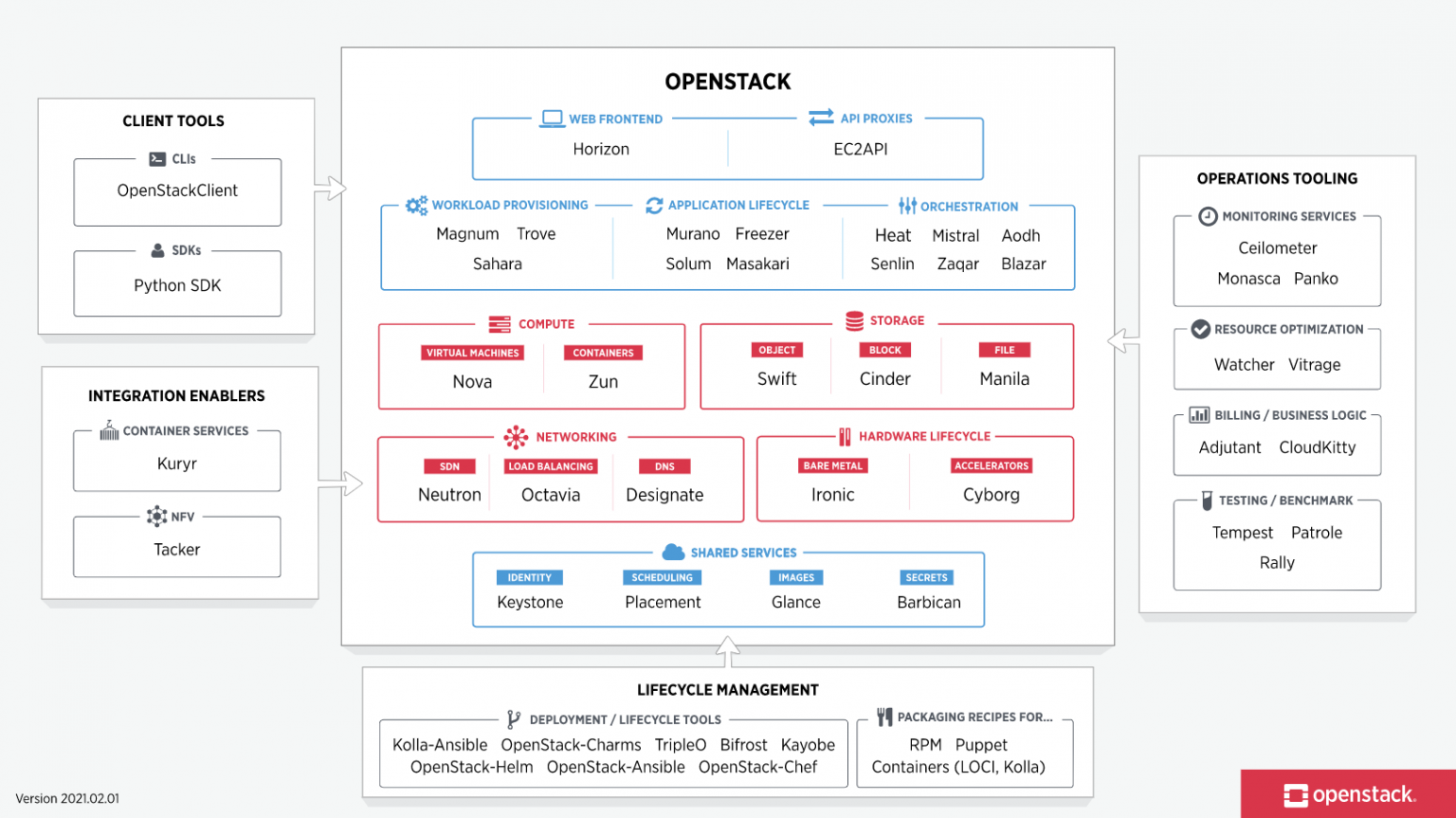
Also OpenStack is broken up into services to allow you to plug and play components depending on your needs. The OpenStack map gives you view of the OpenStack landscape to see where those services fit and how they can work together.